Author: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
Date: June 12, 2017 (Last revised: August 2, 2023)
Link: https://arxiv.org/abs/1706.03762
Attention Is All You Need
Introduction
The paper "Attention Is All You Need" introduced the Transformer, a groundbreaking neural network architecture that revolutionized natural language processing and beyond. This seminal work proposed a new approach to sequence transduction that dispensed with recurrent and convolutional layers entirely, relying solely on attention mechanisms.
Background
Prior to the Transformer, the dominant sequence transduction models were based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. While these models achieved impressive results, they had significant limitations in terms of parallelization and training time.
The Transformer Architecture
The Transformer represents a paradigm shift in how we approach sequence modeling. Here are its key innovations:
Self-Attention Mechanism
The core innovation of the Transformer is its reliance on self-attention mechanisms. Unlike recurrent models that process sequences sequentially, self-attention allows the model to weigh the importance of different positions in the input sequence simultaneously.
The attention function can be described as mapping a query and a set of key-value pairs to an output. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Multi-Head Attention
Instead of performing a single attention function, the Transformer uses multi-head attention, which allows the model to jointly attend to information from different representation subspaces at different positions.
def multi_head_attention(query, key, value, num_heads):
"""
Multi-head attention mechanism
Args:
query: Query tensor
key: Key tensor
value: Value tensor
num_heads: Number of attention heads
Returns:
Attention output
"""
# Split into multiple heads
d_model = query.shape[-1]
depth = d_model // num_heads
# Linear projections
Q = dense_layer(query, d_model)
K = dense_layer(key, d_model)
V = dense_layer(value, d_model)
# Split heads
Q = split_heads(Q, num_heads, depth)
K = split_heads(K, num_heads, depth)
V = split_heads(V, num_heads, depth)
# Scaled dot-product attention
attention_output = scaled_dot_product_attention(Q, K, V)
# Concatenate heads
output = concatenate_heads(attention_output)
return output
Position-wise Feed-Forward Networks
In addition to attention sub-layers, each layer in the encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically.
Positional Encoding
Since the Transformer doesn't use recurrence or convolution, positional encodings are added to the input embeddings to inject information about the relative or absolute position of tokens in the sequence.
Key Results
The experimental results demonstrated the superiority of the Transformer architecture:
Machine Translation Performance
- WMT 2014 English-to-German: Achieved 28.4 BLEU score, improving over existing best results by over 2 BLEU points
- WMT 2014 English-to-French: Established a new single-model state-of-the-art BLEU score of 41.8 after training for just 3.5 days on eight GPUs
Training Efficiency
One of the most remarkable aspects of the Transformer is its training efficiency. The model required only a small fraction of the training costs of the best models from the literature at the time, while achieving superior results.
Generalization
The paper demonstrated that the Transformer generalizes well to other tasks beyond machine translation, successfully applying it to English constituency parsing with both large and limited training data.
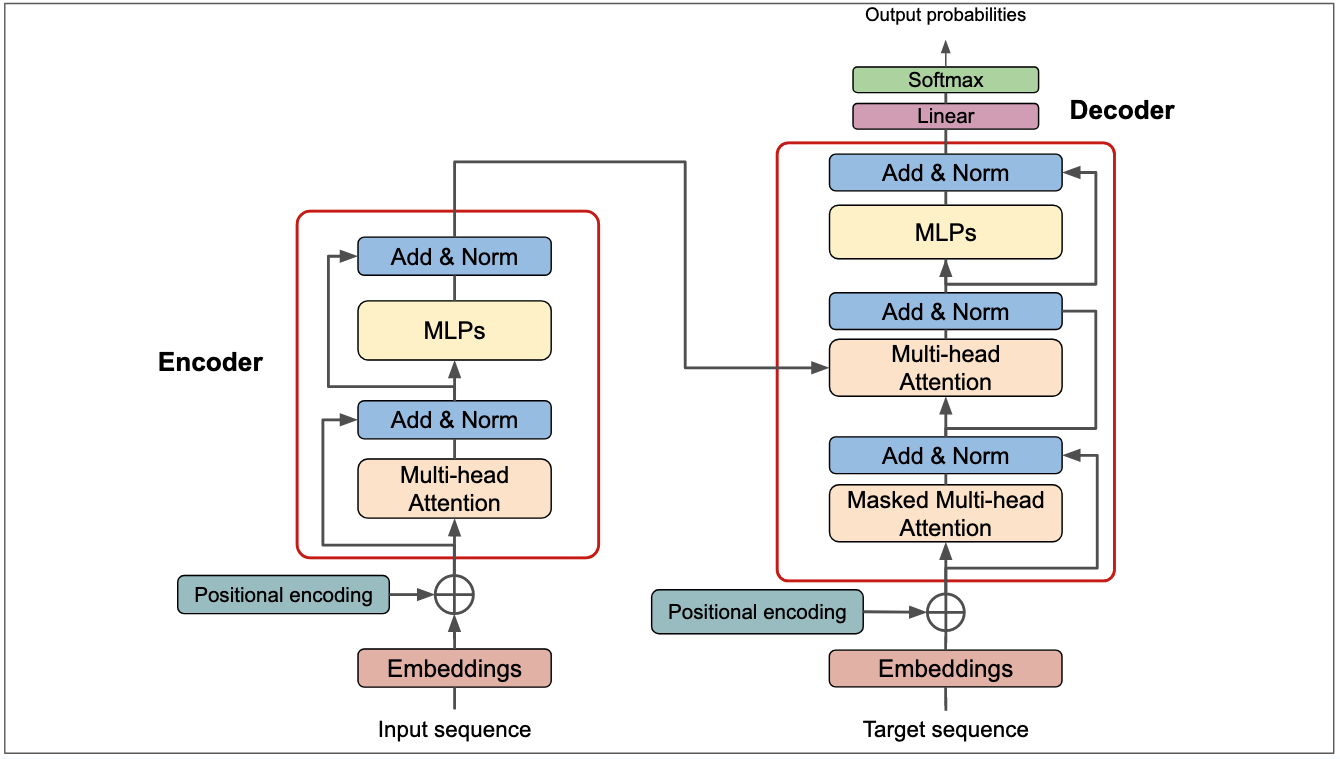
Model Architecture Details
The Transformer follows an encoder-decoder structure:
- Encoder: Composed of a stack of 6 identical layers, each with two sub-layers (multi-head self-attention and position-wise feed-forward network)
- Decoder: Also composed of 6 identical layers, but with an additional sub-layer that performs multi-head attention over the encoder's output
Both the encoder and decoder use residual connections around each sub-layer, followed by layer normalization.
Impact and Legacy
The "Attention Is All You Need" paper has had a profound impact on the field of deep learning:
- Foundation for Modern NLP: The Transformer architecture became the foundation for models like BERT, GPT, T5, and countless others
- Beyond NLP: The architecture has been successfully adapted for computer vision (Vision Transformers), audio processing, and multi-modal learning
- Scalability: The parallelizable nature of Transformers enabled the training of increasingly large models
- Research Direction: Shifted the research community's focus from recurrent architectures to attention-based models
Technical Innovations
Scaled Dot-Product Attention
The attention mechanism uses a scaling factor to prevent the dot products from becoming too large in magnitude:
Attention(Q, K, V) = softmax(QK^T / √d_k)V
Where d_k is the dimension of the key vectors.
Layer Normalization and Residual Connections
Each sub-layer employs a residual connection followed by layer normalization:
LayerNorm(x + Sublayer(x))
This design choice helps with gradient flow and enables training of deeper networks.
Conclusion
"Attention Is All You Need" introduced a revolutionary architecture that transformed the landscape of deep learning. By demonstrating that attention mechanisms alone could achieve state-of-the-art results without recurrence or convolutions, the Transformer opened new possibilities for model design and set the stage for the modern era of large language models and foundation models.
The paper's impact extends far beyond its original application to machine translation, influencing research across multiple domains and becoming one of the most cited papers in modern AI research.
Citation:
@article{vaswani2017attention,
title={Attention is all you need},
author={Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Lukasz and Polosukhin, Illia},
journal={Advances in neural information processing systems},
volume={30},
year={2017}
}